Published
in the Prog C++ section,
on 1 March 2017
Once upon a time, the Qt people joked about switching Qt to
snake_case in one of the April Fools posts.
But even if it was a joke, it did trigger me and Vishesh to talk
(argue?) about it during one of aKademies.
One of the strange things I’ve noticed is that when I’m writing code
that is Qt-based, I tend to use camelCase most of the time,
but at the same time (in the same project) I tend to use
snake_case when I’m creating generic functions. For
example, a for-each algorithm that works on associative containers would
be called for_each_assoc instead of
forEachAssoc. This is the place where Vishesh did not agree
with me.
You might ask me why I’m bringing this up now, quite a few years
after the discussion.
I’ve been digging through Qt code, and I’ve encountered this:
inline QModelIndex create_index(
int row, int column,
QHash<QModelIndex, Mapping*>::const_iterator it) const
{
return q_func()->createIndex(row, column, *it);
}
void _q_sourceDataChanged(const QModelIndex &source_top_left,
const QModelIndex &source_bottom_right,
const QVector<int> &roles);
void _q_sourceHeaderDataChanged(
Qt::Orientation orientation, int start, int end);
void _q_sourceLayoutAboutToBeChanged(
const QList<QPersistentModelIndex> &sourceParents,
QAbstractItemModel::LayoutChangeHint hint);
void _q_sourceLayoutChanged(
const QList<QPersistentModelIndex> &sourceParents,
QAbstractItemModel::LayoutChangeHint hint);
void _q_sourceRowsAboutToBeInserted(const QModelIndex &source_parent,
int start, int end);
void _q_sourceRowsInserted(const QModelIndex &source_parent,
int start, int end);
I’d say that Qt is a true framework for the new age of political
correctness – it does not discriminate against any of the naming styles.
:)
p.s. I’ve posted this just for fun, please do not post comments about
which naming convention is better etc. No reason to start a flamewar
here.
While the rest of the Plasma team is sprinting in Germany, I’m
unfortunately tied down to my chair at home and trying to sprint as
well.
Backends
The main work I’ve been doing since I announced Plasma Vaults was to
refactor the hell out of the Vaults infrastructure to allow me to
support more encryption engines.
I’ll blog about some of the more fun parts of this refactor
later.
The main reason why I am mentioning this now is that we now have two
different choices for Vault encryption.
The first is (as previously mentioned) EncFS, and the newly added one
is the young but promissing CryFS.
Choosing the backend
CryFS is a more modern system that tries not to repeat the same
errors that EncFS (and eCryptFs) have. It does not expose the number of
files, directory organization, nor sizes of the files stored in the
system, while not having any significant known drawbacks.
One thing that I’d like to say here is that the important word in the
above sentence is known.
It is true that EncFS has known security issues thanks to the
independent security audit by Taylor Hornby, so you know that it is not
safe in certain use-cases.
But its huge advantage is that you know what its problems are. For
the newer systems like CryFS, there is no known independent security
audits (if you find one, please notify me).
This means that, at this point, the choice is between a known system
with known faults that you will most likely be safe with if you use it
correctly, and a new system that does not have those faults,
but its faults are unknown.
I’m investigating a few systems more (including eCryptFs), but I’ll
write about them when they get supported by Plasma Vaults.
A bit on the UI
I’ve also been polishing the UI a bit.
Instead of having a huge dialogue, the vault creation is now in a
nice-looking wizard. I’m not a fan of wizards, but in this case it is a
much better choice.
Choosing the cypher and activities
Apart from not looking as cluttered as the previous one, it also
allows different backends to have different options (like choosing the
cypher in CryFS).
Fun with icons
Alex has made a few nice icons for this, and now I’m experimenting
how can I use them to improve the user experience.
Icons
One of the things I’m trying out is to set the default icon for the
vault folder, so that, when you open the Vault, its folder’s icon
changes to notify you that that its contents is encrypted.
Five years ago
(I’m completely shocked how the time flies), we were working on Plasma
Active, and one of the ideas was to allow the user to create private
activities in which all the data would be encrypted.
Now, while the idea itself was solid, there were big problems with
its realization. There was no way to force applications to separate the
configuration and other data based on whether the user is in the
encrypted activity or not. Especially since the same application can run
in multiple activities.
For those reasons, the idea was abandoned. I didn’t like the fact
that I spent a lot of time on it just for it to be thrown away, so
encryption always stayed in my mind.
Enter Plasma Vaults
If the idea to have activities encrypted can not work because of the
things not controllable by us, then we need to do something more obvious
and transparent, so that the user can know exactly which data is secure,
and which not.
Instead of having something as abstract as an activity
encrypted, Plasma Vaults will allow you to create encrypted
directories.
Sometimes we want to keep specific documents private. Sometimes we
are actually forced to do so (I’ve seen enough work contracts that force
you to keep the job-related data as secure as you know how to). And
sometimes we have to share our computer with others while keeping our
data completely private.
Plasma Vaults allow you to easily create and manage EncFS encrypted
directories (other encryption systems might be supported in the
future).
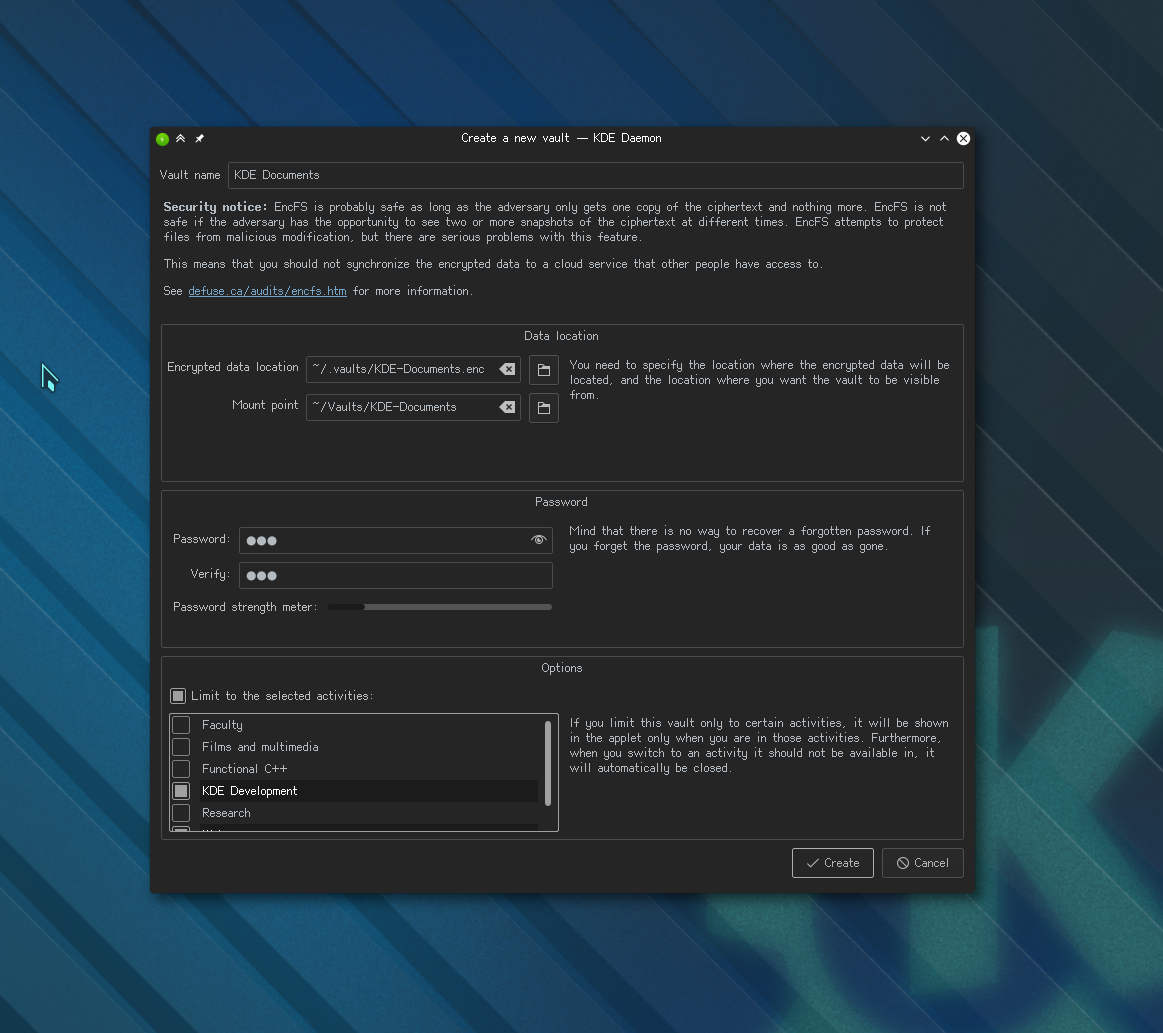
Creating a new vault
The vault creation dialogue will need more work. While most of the
text in it is important, we’ll need to think of something to make it
less daunting to look at.
Activities
One of the things that did not survive from the original concept is
that the encrypted drive is tightly bound to an activity.
But still, that does not mean there can not be a connection between
them. The vaults are usually related to the projects that we work on,
and one of the main use-cases of activities is the project handling.
So, for each vault, you can choose which activities it should be
available on. It will not be automatically unlocked when you enter said
activities, but it will be automatically closed when you exit them.
Applet for handling vaults
This might be a bit annoying if you often switch between activities,
but I’d always put security above convenience.
UI
Currently, the UI is not as polished as it should be. Some of the
problems are in the Plasma Vault code itself, but some are in the KF5
widgets.
Password dialogue
Alternatives
This is not the only way to keep your data private. Lately, most
Linux installers allow you to create an encrypted home partition, or to
encrypt the whole system including the swap.
But these cover a different use-case. They cover the case when your
device gets lost while turned off.
They do not cover the possibility that someone might access your
system while it is running. Plasma Vaults fill this void by making the
attack surface smaller – instead of having all data unlocked at once,
you can do it piece by piece – it is more granular.
This does not mean that using only Plasma Vaults will make your data
more secure than encrypting the whole system, it just covers a different
set of possible attacks. It is probably worth it to combine both if you
are doing really secret work.
Published
in the Prog C++ section,
on 28 January 2017
I’ve got a chance to share a part of my upcoming book here. It is an
excerpt from the second chapter.
FP in C++
The main feature of all functional programming languages is that
functions can be treated like ordinary values. They can be saved into
variables, put into collections and structures, passed to other
functions as arguments, and also returned from other functions as
results.
Functions that take other functions as arguments, or that return new
functions are called higher-order functions. Higher-order functions is
probably the most important concept in functional programming. As you
might know, programs can be made more concise and efficient by
describing what the program should do on a higher level, with the help
of standard algorithms, instead of implementing everything by hand.
Higher-order functions are indispensable for that. They allow us to
define abstract behaviours and more complex control structures than
those provided by the C++ programming language.
Published
in the Prog C++ section,
on 21 November 2016
I’ve just returned from Meeting C++.
There were couple of really nice talks – some less technical like the
one from Jon Kalb of CppCon to the low level ones like the Rainer’s talk
about the memory model of C++. Also, seing Bjarne Stroustrup in-person
was a pleasure.
Sadly, I was not able to watch all the talks that I wanted (including
Arne’s), but I plan to do so once the recordings are posted online.
My talk was about functional design and reactive programming. The
slides are available here. I’ll post the link to
the recording as soon as it is uploaded.
Unfortunately, there was no support for DisplayPort nor VGA at the
venue, and I didn’t have a HDMI adapter on me, so I had to give my
presentation from a friend’s computer (thanks Goran!) without any demos,
but I’d say it all went well.
Next year, I’ll probably give a talk about immutable (aka functional)
data structures. We’ll see. :)