So, how to make this available to the normal users, you ask? Easy -
make it available to the normal file managers via KIO - just type
activities:/ in Dolphin, Konqueror or the Folder View applet, and you’ll
get a list of all activities, and files that belong to them.
You can see what it looks like in the screenshots. At the moment, it
is a bit buggy, but it will work as expected for SC 4.9.
Seems I’ve realized I haven’t been blogging for too long and now I’m
writing too much.
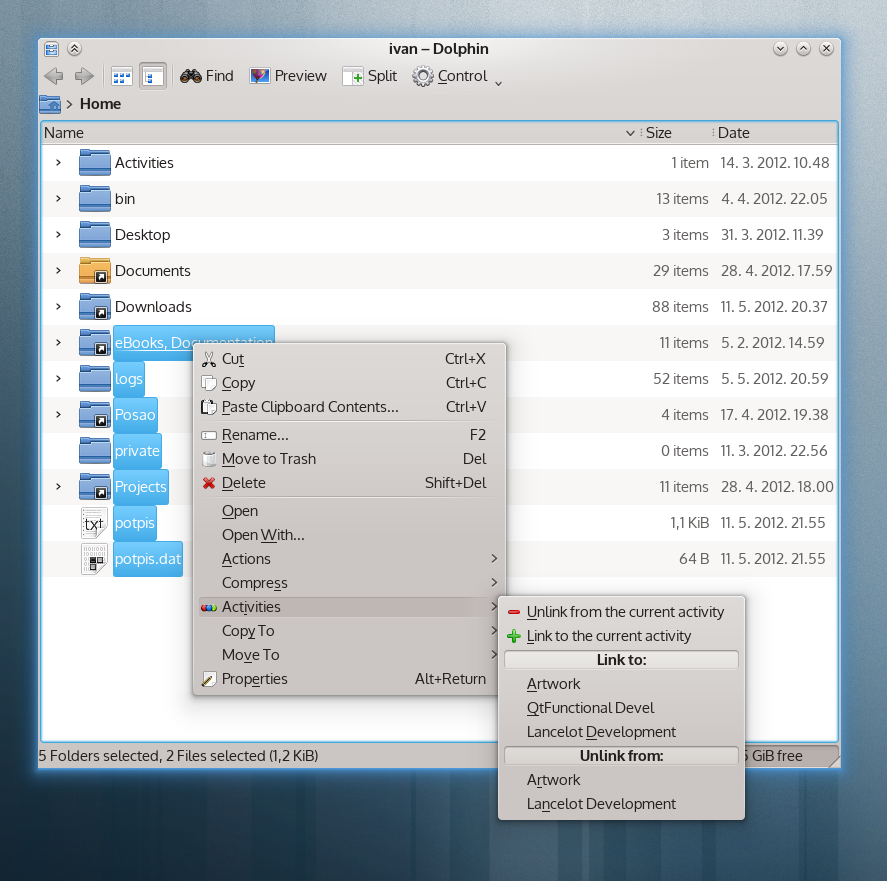
The new fun and fancy feature of Activities is being able to link
files and folders to activities by right-clicking them in Dolphin,
Konqueror, Folder View. You can see what it looks like in the
screenshots.
The first screenshot shows the menu for a single file, while the
second shows it for a multi-item selection.
What’s the point?
Activity linkingDesktop
Currently, this doesn’t do much - you can show the linked files on
your desktop if you set your desktop layout to be contour (not the whole
Plasma Active, but only the widget layout).
And soon, I’m planning to also have a KIO implemented so that you can
browse all the linked files by browsing activities://something/…
I’m no longer sponsored by basysKom to work on Active (the Contour
project ended), so I can focus some of my coding to the desktop. Most of
the things I’ve been doing are independent from Plasma Active, but had a
small UI overlay written specifically for it.
Now is the time to bring some of the features that proved to be
useful to common Plasma users, and, for this, I’ll need help from
everyone, be it brainstorming or even coding. This post is meant to
introduce to you what technologies are going to be available to build
upon.
Background: One of the purposes of activities is to link documents
(including web pages, images, etc.), applications, contacts etc. that
are related to the activity so that you can access them faster. Apart
from manually telling the system which resources belong to an activity,
the goal is to have the system score the documents based on the number
of times you’ve used them in a specific activity*.
So here are some of the ideas I plan to make reality.
Manual linking of files by right-clicking them in
dolphin.
Linking via Share-Like-Connect applet - eventually, when most of
our applications get patched to report the documents they open to the
activity manager, we’ll know which document is in focus at any given
time. This way, we’ll have global (in the panel) buttons to share the
document, bookmark it, link it to the activity.
Linking contacts from Kontact, Telepathy and similar
Linking the highest scored documents automatically or
semi-automatically
Have the favourite applications section in menus dependent on the
activity
Rank krunner results according to the scores
Browsing the resources that belong to the activity with Dolphin
(and file open/save dialogue)
Showing all that in the Shelf applet
actually, it is a little bit more complex than that, but it is
irrelevant for this purpose.
Other simpler things
System settings module for advanced activity configuration - the
name and icon setup plasma provides is a bit underwhelming
Setting the basic activity info, creating and deleting
Setting whether the activity is private (requires a password to be
unlocked, data is encrypted) - see Encryption in KDE SC
Setting whether the usage statistics should not be collected in a
specific activity at all, or only for certain applications
Dreams
Automatic grouping of documents that relate to each other based on
the usage statistics (for example, the literature you used while writing
a scientific paper)
…
Help
So, the thing that I need from all of our awesome users is to polish
these ideas, create new and more awesome ones, etc.
One of the problems that the Nepomuk team had in the past were
crashes in the strigi library (usually because of a corrupted file or
similar). For that reason, the indexer was moved into a separate
process, and it was executed for each file individually.
This is generally a good practice - ensuring that components can not
crash the main server. For those who don’t know this, Nepomuk server
invokes a few out-of-process services so that those can’t crash each
other. And, as already stated, the file indexer service delegates the
work to an external process. This is a rather nice design - hierarchical
separation of risky components into external processes.
While this brings stability, it is not cheap. Launching processes
takes valuable CPU time (loading, linking and other things your OS does
whenever you start a program). This is not a big issue for Nepomuk’s
services since there are only a few of them, and they are started only
once, when the system boots.
But it was the issue with the indexer since the executable was being
run for each file that needed indexing. This is not something that I was
comfortable with, so I decided to make it a bit more sophisticated,
without decreasing stability.
Now, the external indexer process is started only once, and the
server feeds it with a list of files that need indexing - one by one. If
the indexer crashes, the server just restarts it and continues without a
glitch.
Nepomuk is a very nice shared data repository. It is an easy way to
make the data from your application available to others.
But, it is important to know that Nepomuk is not a general purpose
database - everything is peachy until you start using it as such. And
especially if you start treating it as a relational database.
There are a few things to keep in mind when developing Nepomuk-based
programs.
Working on graphs
RDF
So, any query you make is not a restriction on a relation (a table)
but rather a multi-join of a single subject-verb-object table (this is a
bit simplistic view).
As you probably know, doing joins is not really a cheap operation
however optimized it is (and Virtuoso is one of the fastest
graph databases available).
D-Bus connections
The second thing is that while Nepomuk-internal connections are done
via local sockets, your connection to Nepomuk goes through D-Bus which
is not the fastest kid on the block. The more requests you make, the
more time it will take.
Some hints
There are some things you can make to make these issues less relevant
to your applications.
Wide-table queries
One of the common ways people write queries is the following:
select ?r where {
?r a something .
?r something else .
...
}
And then process the results one by one by doing stuff like:
Which means your program creates a lot of queries - one main, and a
couple more for each result.
Instead of making a lot of queries, it is advisable (although
initially not that intuitive) to create one big query like this:
select ?r, ?prop1, ?prop2 where {
?r a ?prop1 .
?r something ?prop2 .
...
}
It does transfer a lot of data at once, but at least it does so in a
single request-response connection, and it doesn’t repeat the same query
(parsing, optimizing, evaluating) multiple times for different
parameters.
Consider storing some data
locally
If you have data that don’t necessarily need to be shared, consider
storing it in config files, embedded database like sqlite3 or
similar.
This way, apart from skipping D-Bus, you can have faster queries in
the cases like these (which are not at all rare):
select ?r where {
?r a someType .
?r property1 "value1" .
?r property2 "value2" .
...
}
This query does a number of joins, whereas its equivalent in SQL does
only filtering:
select * from someType where
property1 = "value1" and
property2 = "value2" and
...
Summary
So, whatever you do (be it Nepomuk or something else), first ask,
experiment, test and learn the system before using it.