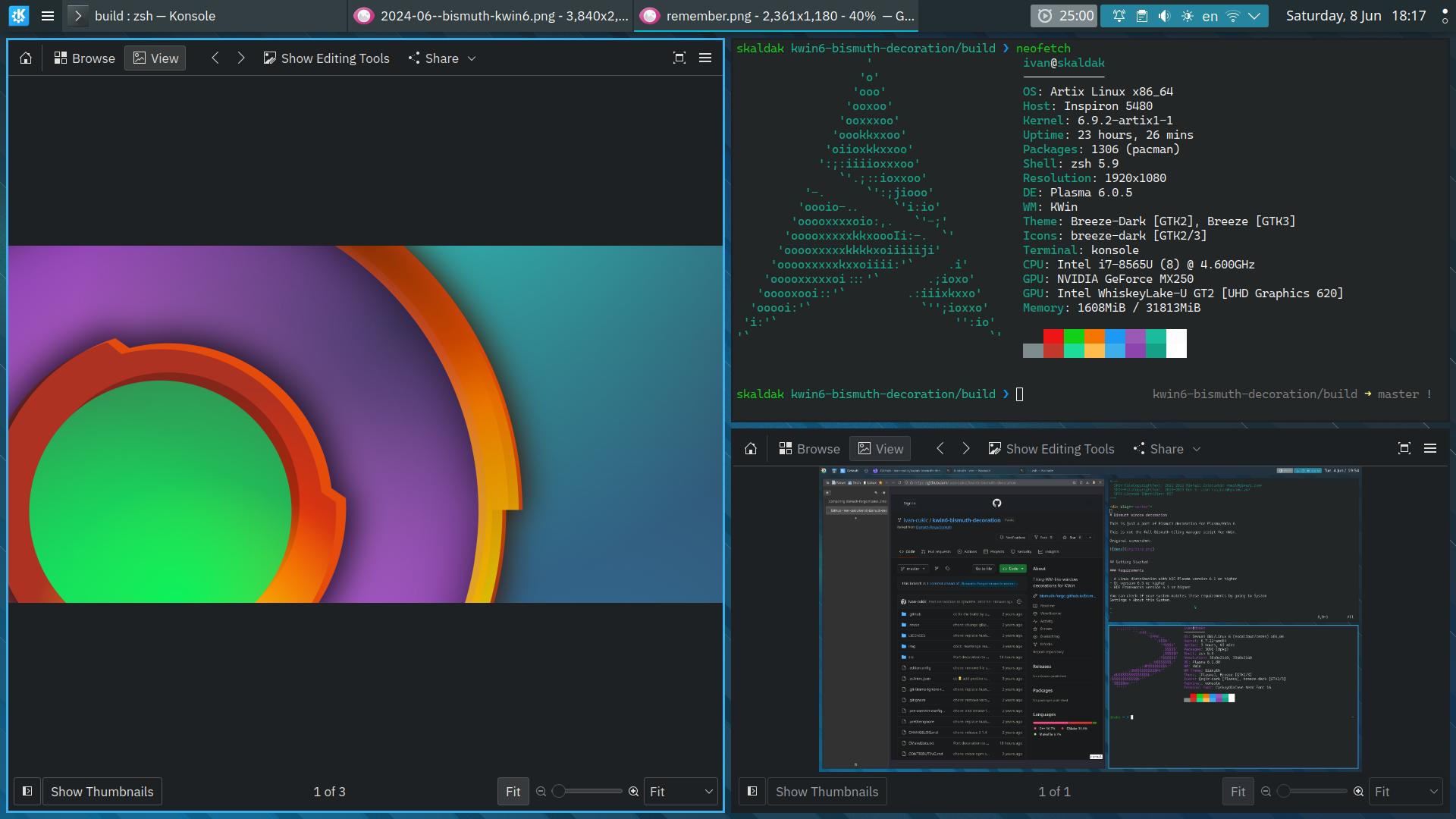
I was keeping myself on Plasma 5.x until recently. I got so
accustomed to the Bismuth window tiling script for KWin that I couldn’t
imagine myself updating to Plasma 6.x where Bismuth doesn’t work.
Unfortunately (?), one of the recent Debian updates broke Bismuth in
Plasma 5.x as well, so I had nothing keeping me on the old version
anymore. I’m now (again) running the development version of (most) KDE
software.
Since the update, I managed to make the Qtile tiling window manager
work with Plasma to some extent. But the integration between Qtile and
Plasma I hacked was less than ideal, and I kept switching between KWin
which worked perfectly, as KWin does, but without tiling, and my
Frankenstein Qtile which didn’t work that well, but it had tiling.
Maybe I’ll write about it if I get back to hacking Qtile, but that
might not happen any time soon because…
Huge kudos to all who are involved in the rebirth, the script works
as well as it did with KWin 5.
Window decoration
The only thing missing was the simple ‘just a line around the window’
window decoration that Bismuth had.
KWin 6 and Krohnkite + Bismuth decoration
Now we have that as well, I’ve ported the original Bismuth window
decoration to KWin 6 (nothing huge, just a few tiny changes to make it
compile). The code, and the installation instructions are available on
github.
Published
in the Shares section,
on 17 February 2024
Some time ago, Marco started a series of articles on SObjectizer. It
is starting to become the source for all things
SObjectizer – it is currently at post number 19 – quite an
endeavour.
For those who haven’t met SObjectizer before, it is a framework for
writing concurrent applications which supports the actor model,
publish-subscribe…
Published
in the Shares section,
on 28 December 2023
People who have visited any of the larger C++ conferences surely know
Rainer Grimm, know his talks, workshops and books.
Rainer Grimm
Unfortunately, he has been diagnosed with ALS, a serious progressive
nerve condition.
Since ALS research doesn’t get much attention or funding, Rainer
started a fund raising campaign for funding ALS research with
ALS-Ambulanz of the Charité and I Am ALS organization.
Some time ago, I wrote a post about integrating
Qt’s associative containers with the fancy new C++ features, range-based
for loops with structured bindings.
That post inspired KDAB’s own Giuseppe D’Angelo to add the
asKeyValueRange member function to both QHash
and QMap. Now it’s possible to iterate over them with a
simple range-based for loop, like so:
for (auto [key, value] : map.asKeyValueRange()) {
// ...
}
The second part of my previous post demonstrates how we can iterate
over Qt SQL results using a range-based for loop as if it were an
ordinary collection.
This post covers what is needed to be able to traverse the SQL
results in a much nicer and safer way like so: