Published
in the Prog C++ section,
on 19 February 2019
There are only a few things more fun in this world than doing
template meta-programming (TMP) and reading all those long poems that
the compiler writes out when we make even the smallest mistake.
While we don’t usually welcome these messages, there are ways to make
them useful.
One of the main causes of errors in TMP code are unexpected types –
types that the compiler is deducing instead of the types that we expect
it to deduce.
This results in error messages occurring in seemingly random places
in our code.
printf debugging
Just like it is sometimes useful to printf values in our
program while debugging a problem, it can be useful to print types while
debugging the problems in TMP code.
For this, here is one of my favourite meta-functions for C++:
template <typename... Ts>
struct print_types;
It is a meta-function that takes several arguments, but has no
implementation. Which means that every time we try to use it, the
compiler will report an error along with some additional information
like which Ts... we passed to the meta-function.
For example, if we wanted to know what are the exact types of
std::vector<bool>::reference and friends, we could do
this:
And the compiler will print out an error message along these
lines:
invalid use of incomplete type 'class print_types<
std::_Bit_reference,
bool,
std::_Bit_iterator
>'
The compiler printed out all three types that we requested it to
print.
This can be used in conjunction with some compiler output
post-processing – shortening some type names like
std::basic_string<char> to string etc,
replacing < and > with (
and ) and putting the output through
clang-format to get a pretty readable and nice formatted
output for complex types.
For example, this is the output generated for one expression template
in my codebase:
The problem with the previous approach is that you can call
print_types only once – as soon as the compiler encounters
it, it will report an error and stop.
Instead of triggering an error, we might want to try something else –
something that the compiler reports without stopping the compilation –
we could trigger a warning instead.
One of the easiest warnings to trigger is the deprecation warning –
we just need to mark the print_types class as
[[deprecated]].
This way, we can use it multiple times and the compiler will generate
a warning for each of the usages. Now, this works well with clang
because it reports the whole type that triggered the warning. Other
compilers might not be that detailed when reporting warnings so your
mileage might vary.
Assertions on types
When you write TMP code, it is useful to assert that the types you’re
getting have some desired property.
For example, it is a sane default (just like const is a
sane default for everything) to expect all template parameters to be
value types. For this, you could create an assertion macro and sprinkle
it all over your codebase:
#define assert_value_type(T) \
static_assert( \
std::is_same_v<T, std::remove_cvref_t<T>>, \
"Not a value type")
Having the habit of adding assertions like these can make your life
much easier down the road.
Tests on types
Just like the original print_types we defined stops the
compilation when called, static_assert stops compilation as
soon as the first one fails.
What if we wanted just to get notified that a test failed, without it
stopping the compilation.
We can use the same trick we used to allow print_types
to be called several times. We can use the [[deprecated]]
annotation to get a warning instead of getting an error with
static_assert.
This can be implemented in several ways. The main gist of all the
solutions is to create a class template which is then specialized for
false or std::false_type and that
specialization is marked as deprecated.
Published
in the Prog C++ section,
on 9 February 2019
This will be a short post about a feature in STL that seems to be not
as well-known as it should be.
Imagine we want to create a small function that collects files in the
subdirectories of the current directory. So, a list that would be
returned by ls */*.
Note that namespace fs = std::filesystem; is used in the
examples.
We’ll start by creating a function that returns filenames of all
files in the specified directory.
This function creates a vector of all files in a specified directory
using the STL’s filesystem library.
What we need to do now is create a function that calls
files_in_dir for all directories in the current directory
and collect all the results in a single vector.
std::vector<fs::directory_entry>
files_in_subdirs()
{
std::vector<fs::directory_entry> results;
auto item = fs::directory_iterator{"."};
const auto last = fs::directory_iterator{};
for (; item != last; ++item) {
if (!item->is_directory()) {
continue;
}
auto dir_items = files_in_dir(*item);
[ Add everything from dir_items into results ]
}
return results;
}
The function should be easy to understand – it is just iterating
through subdirectories of the current directory, and calls
files_in_dir to get the list of files in them.
The question that remains is how to add those collected items into
the resulting vector.
We can use .insert to insert all items from
dir_items into the results vector:
The problem is that this will copy all the
directory_entry values from dir_items to
result. The copies are unnecessary because
dir_items is destroyed immediately afterwards.
We could have moved everything into the results
vector.
If we didn’t know any better, we could replace this insert with a for
loop that moves the elements from dir_items to
results one by one (we would need to call
reserve before to eliminate the possibility of vector
reallocations).
But we do know better – there is an iterator adaptor that returns
rvalue references when it is dereferenced and it is aptly named
std::move_iterator.
std::move_iterator is an iterator adaptor which behaves
exactly like the underlying iterator, except that dereferencing converts
the value returned by the underlying iterator into an rvalue. (cppreference.com)
This means that we can still rely on higher abstraction functions
like .insert and still be efficient. We just need to pass a
move iterator to .insert instead of the normal one:
As today is the Privacy Day, here’s another post about privacy in KDE
software.
As you are probably aware, KDE software uses the Qt library
extensively. As do many other 3rd party applications.
Passwords
Most of these applications use the Qt’s default text component –
QLineEdit – when they need password input, because
QLineEdit has a nice convenient mode where it masks the
content of the text field – it shows asterisks or circles instead of the
actual characters it contains.
This is a nice way to block over-the-shoulder snooping, and is a
common approach to do password entry even in non-Qt software.
The underbelly
In order to see what the problem here is, we need to understand how
components like QLineEdit work.
While the typed characters are not shown to the user, they
are stored somewhere. Usually in a string variable as plain
text (not encrypted). This means that is someone can see the contents of
the process memory while the user types in the password, it will be easy
to read it (problem 1).
Other problems are due to how dynamic memory works on our computers.
String data is stored (usually) in the dynamic memory. When
QString wants to store its data, it will reserve a chunk of
memory and start filling it while the string grows (in this case, while
the user is typing the password). When that chunk is filled, a new
larger chunk is allocated and the data from the old chunk is copied into
it. The old chunk is freed/deleted so that some future memory
allocation can use the same space.
When the QLineEdit is destroyed, so is the
QString variable that stores the password. But, while the
buffer that QString uses to store the data is
freed/deleted, its contents remain in memory until some other
dynamically allocated object is created in the same memory space and
overwrites the data. This is because QString does not fill
its buffer with zeroes on destruction. This means that the passwords
remain in memory for much longer than needed (problem 2).
The dynamic memory is like graffiti - the old content
remains until somebody paints over it
Furthermore, because of string reallocation on resizing (creating a
bigger chunk of memory and copying the old data into it), it is quite
possible that, while the user is typing the password, that the string
will be resized/reallocated at least once. This means that partial
passwords (data from the buffer in the string before reallocation which
is not zeroed-out) will remain in memory until something else overwrites
them (problem 3).
All this memory can end up written to the HDD/SSD if the application
is moved to swap by the OS (problem 4).
Small potatoes
Before you throw your computer into the fireplace, and go to the
tried and tested coding systems of (c)old, we need to see how big these
problems really are.
Reading passwords stored in the process memory can be done from that
same process. This is usually benign because if you’re entering a
password into an application, you probably trust it with said password.
This can only become a problem if that application has a plugin system
(with native code) and you install untrusted plugins.
This should not be a common case. Usually, privacy-aware people do
not use untrusted software.
Reading memory from a separate process is a different story. This is
not possible on a hardened system, but most Linux distributions tend to
be developer-friendly, and this means that they allow attaching a
debugger to a running process with PTRACE. And a debugger
(or any process that pretends to be a debugger) can read the memory of
the process it is attached to.
If you want to block processes from controlling each other, disable
PTRACE.
Regardless of whether PTRACE is enabled or not, for this
to be a problem, you need to be running untrusted software that could
try to extract the passwords from a process’ memory.
It is worth noting that even in the worst case scenario in which an
attacker is allowed to read the memory of your processes either
through a plugin or through PTRACE, finding the password
(or other secret data) is like searching for a needle in a huge
haystack. Normal programs tend to be filled with strings.
Furthermore, if an attacker is allowed any of this, your system is
seriously compromised.
Current improvements
I’ve started this post explaining 4 different problems of using
QLineEdit for password input. I’m glad to say that two of
them do not exist anymore.
The latest version of Qt includes two patches (by yours truly) which
remove the problem of passwords remaining in the dynamic memory of a
process after the input component is destroyed. Namely, when
QLineEdit is used for password input, it will fill the
memory where the password was stored with zeros. Furthermore, it will
preallocate a buffer for the password which is long enough so that
string reallocations don’t happen for 99.99% of users.
This means that problems 2 and 3 are no longer present if you are
using the latest version of Qt.
The fourth problem – the operating system moving the application that
asks you for the password to the swap should also not happen in common
usage. Since problems 2 and 3 are gone, the only time when the password
is in memory is while you’re typing it and the OS is not going
to swap an application that you are currently using.
If you don’t think this is secure enough, you can either disable the
swap on your system or encrypt it.
Disabling the swap partition is often a good idea. Security- and
performance-wise. But only if you have enough system memory, and if you
do not use suspend-to-disk.
The last problem
The last remaining problem is that the password is stored
non-encrypted in memory. Luckily, thanks to the previously mentioned
patches, this is a much smaller issue than it seems at first.
The password is in memory only while it is being entered/used. Which
means that the window that the attacker has to try to get it is
extremely narrow.
Unfortunately, this problem can not be fixed completely. If the
password was kept in memory encrypted, the encryption key would need to
be readily available (in memory) for the application to be able to use
the password. Which means that while your password would be encrypted,
the key to decrypt it wouldn’t.
So, the attacker could try to find the encryption key, then find the
encrypted password, and then decrypt the password.
Now, this would be much harder to do than finding an unencrypted
password. The attacker would need to find two separate things (located
in different parts of the process memory) and would not be able to use
any type of string analysis when searching for the chunks of memory
where the secrets are stored. The encryption key would be a true random
set of bytes, and the encrypted password would look like a
random set of bytes – they would not look like strings at all.
Unfortunately, this is not something that can be fixed in
QLineEdit. This will need a custom password edit component
that uses a safe string implementation instead of
QString.
I’ll try to provide a more general look at what projections are – not
only in the context of ranges. I recommend reading Ryou’s post before or
after this one for completeness.
Tables have turned
Imagine the following – you have a collection of records where each
record has several fields. One example of this can be a list of files
where each file has a name, size and maybe something else.
Collections like these are often presented to the user as a table
which can be sorted on an arbitrary column.
Tables are everywhere
By default std::sort uses operator< to
compare items in the collection while sorting which is not ideal for our
current problem – we want to be able to sort on an arbitrary column.
The usual solution is to use a custom comparator function that
compares just the field we want to sort on (I’m going to omit namespaces
for the sake of readability, and I’m not going to write pairs of
iterators – just the collection name as is customary with ranges):
There is a lot of boilerplate in this snippet for a really simple
operation of sorting on a specific field.
Projections allow us to specify this in a much simpler way:
sort(files, less, &file_t::name);
What this does is quite simple. It uses less-than for comparison
(less), just as we have with normal std::sort
but it does not call the operator< of the
file_t objects in order to compare the files while sorting.
Instead, it only compares the strings stored in the name
member variable of those files.
That is the point of a projection – instead of an algorithm testing
the value itself, it tests some representation of that value – a
projection. This representation can be anything – from a member
variable, to some more complex transformation.
One step back
Let’s take one step back and investigate what a projection
is.
Instead of sorting, we’re going to take a look at
transform. The transform algorithm with an added projection
would look like this:
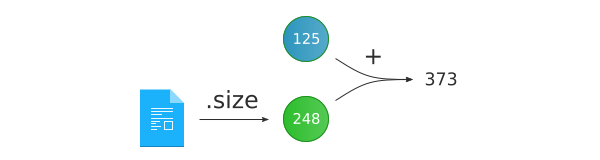
We’re transforming a collection of files with a
&file_t::size projection. This means that the
transform algorithm will invoke the provided lambda with
the file sizes instead of file_t objects themselves.
The transformation on each file_t value in the
files collection is performed in two steps:
First, for a file f, extract f.size
Second, divide the result of the previous step by 1024
This is nothing more than a function composition. One function gets a
file and returns its size, and the second function gets a number and
divides it by 1024.
If C++ had a mechanism for function composition, we
would be able to achieve the same effect like so:
Just like in the previous example, the all_of algorithm
is not going to work directly on files, but only on their sizes. For
each file, the size will be read and the provided predicate called on
it.
And just like in the previous example, this can be achieved by simple
function composition without any projections:
The question that arises is whether all projections can be replaced
by ordinary function composition?
From the previous two examples, it looks like the answer to this
question is “yes” – the function composition allows the algorithm to
“look” at an arbitrary representation of a value just like the
projections do. It doesn’t matter whether this representation function
is passed in as a projection and then the algorithm passes on the
projected value to the lambda, or if we compose that lambda with the
representation function.
Unary function composition
The things stop being this simple when an algorithm requires a
function with more than one argument like sort or
accumulate do.
With normal function composition, the first function we apply can
have as many arguments as we want, but since it returns only a single
value, the second function needs to be unary.
For example, we might want to have a function size_in
which returns a file size in some unit like kB, KiB,
MB, MiB, etc. This function would have two arguments –
the file we want to get the size of and the unit. We could compose this
function with the previously defined lambda which checks whether the
file size is greater than zero.
N-ary function composition
sort needs this to be the other way round. It needs a
function of two arguments where both arguments have to be projected. The
representation (projection) function needs to be unary, and the
resulting function needs to be binary.
Composition needed for sorting
Universal projections
So, we need a to compose the functions a bit differently. The
representation function should be applied to all arguments of an n-ary
function before it is called.
As usual, we’re going to create a function object that stores both
the projection and the main function.
This is quite trivial – it calls m_projection for each
of the arguments (variadic template parameter pack expansion) and then
calls m_function with the results. And it is not only
trivial to implement, but it is also trivial for the compiler to
optimize.
Now, we can use projections even with old-school algorithms from STL
and in all other places where we can pass in arbitrary function
objects.
To continue with the files sorting example, the following code sorts
a vector of files, and then prints the files to the standard output all
uppercase like we’re in 90s DOS:
So, we have created the projected_fn function object
that we can use in the situations where all function arguments need to
be projected.
This works for most STL algorithms, but it fails for the coolest (and
most powerful) algorithm – std::accumulate. The
std::accumulate algorithm expects a function of two
arguments, just like std::sort does, but it only the second
argument to that function comes from the input collection. The first
argument is the previously calculated accumulator.
Composition for accumulation
This means that, for accumulate, we must not project all
arguments – but only the last one. While this seems easier to do than
projecting all arguments, the implementation is a tad more involved.
Let’s first write a helper function that checks whether we are
processing the last argument or not, and if we are, it applies
m_projection to it:
Note two important template parameters Total – the total
number of arguments; and Current – the index of the current
argument. We perform the projection only on the last argument (when
Total == Current + 1).
Now we can abuse std::tuple and
std::index_sequence to provide us with argument indices so
that we can call the project_impl function.
The call_operator_impl function gets all arguments as a
tuple and an index sequence to be used to access the items in that
tuple. It calls the previously defined project_impl and
passes it the total number of arguments (sizeof...(Idx)),
the index of the current argument (Idx) and the value of
the current argument.
The call operator just needs to call this function and nothing
more:
We will have projections in C++20 for ranges, but projections can be
useful outside of the ranges library, and outside of the standard
library. For those situations, we can roll up our own efficient
implementations.
These even have some advantages compared to the built-in projections
of the ranges library. The main benefit is that they are reusable.
Also (at least for me) the increased verbosity they bring actually
serves a purpose – it better communicates what the code does.
A bit more than a year ago, the KDE community decided to focus on a
few goals. One of those goals (the most important one as far as I’m
concerned) is to increase the users’ control over their private
data.
KDE developers and users have always been a privacy-minded bunch. But
due to all the fun things that have happened in the recent
years, we had to switch to the next gear.
We have seen new projects like KDE Itinerary (by Volker),
Plasma Vault (by yours truly), Plasma Mycroft (by Yuri and Aditya), etc.
There has also been a lot of work to improve our existing projects like
KMail.
Now, this post is not about any of these.
It is about a KDE Privacy developer sprint organized by Sando
Knauß.
The sprint will be held in Leipzig (Germany) from 22. 3. to 26. 3.
and all privacy-minded contributors are invited to join.